Het Probleem
ClickHouse is snel, tot het dat niet is. Een query die gisteren 200ms duurde, neemt opeens 30 seconden in beslag en je moet uitzoeken waarom. Of een query faalt met een cryptische foutmelding en je wil weten wat er gebeurd is.
Het ingebouwde /play endpoint laat je queries uitvoeren, en dat is vrijwel alles. Geen profiling, geen geschiedenis, geen manier om te zien wat een query écht doet. Je eindigt met handmatige queries tegen system.query_log, system.trace_log en een handvol andere systeemtabellen, timestamps en IDs met de hand aan elkaar knopen.
De tools die wél bestaan (CHUI, diverse GUI clients) zijn gebouwd voor het uitvoeren van queries. Een trage query debuggen of een foutmelding onderzoeken? Niet hun focus. Er was niets dat de systeemtabellen van ClickHouse behandelde als een volwaardige debugging-interface.
Dus ik bouwde er een. Nou ja, ik vibecoded er een.
Wat Is Het?
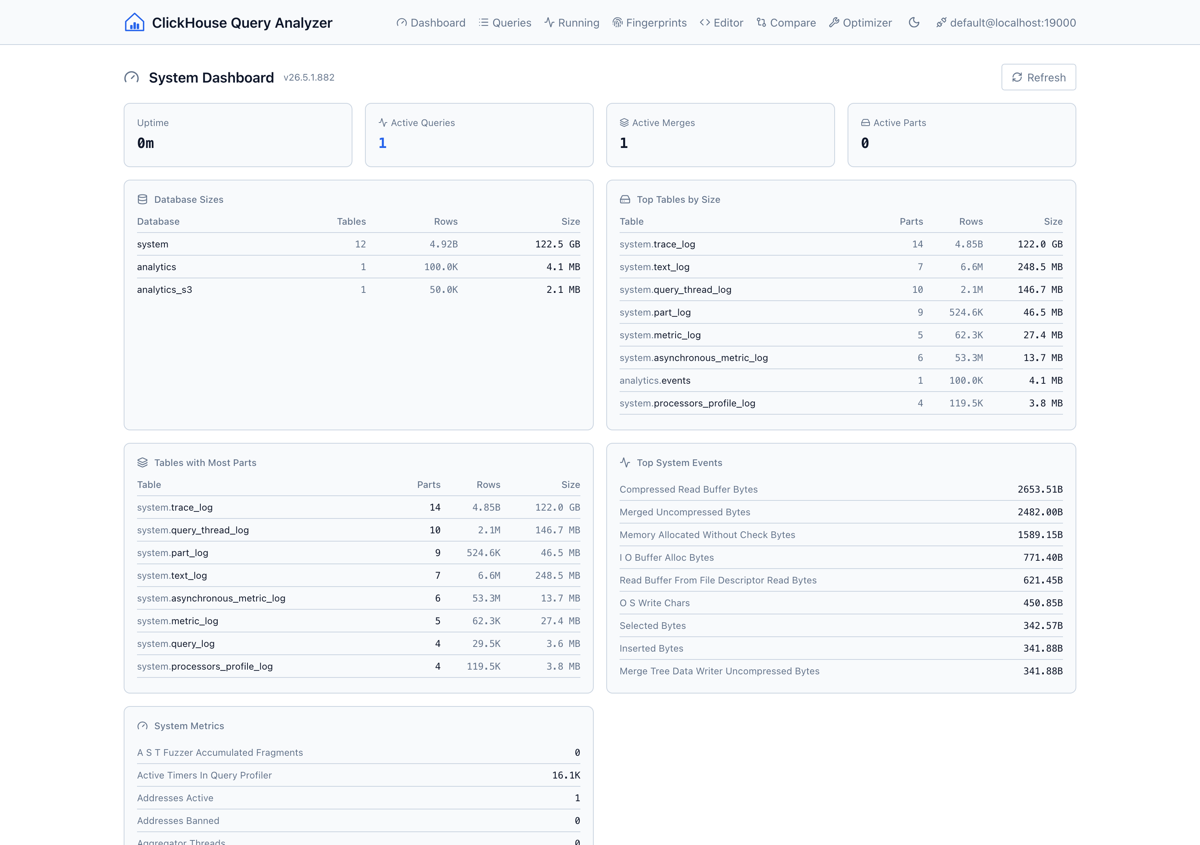
ClickHouse Query Analyzer is een single-binary web applicatie die verbindt met elke ClickHouse instance en je een fatsoenlijke debugging-werkplek geeft. Je start het, configureert het met je ClickHouse server, en krijgt flame graphs, thread-analyses, query fingerprints, een SQL editor met schema browser en een tabeloptimalisatie-tool die concrete DDL-aanbevelingen genereert.

Geen database om in te stellen. Geen config-bestanden. Geen state op de server. Verbindingsparameters worden per-request vanuit de browser meegestuurd, dus de backend blijft stateless.
Query Analyse
De querylijst haalt data uit system.query_log met filters voor tijdsbereik, gebruiker, query-soort, minimale duur, geheugengebruik en full-text zoek. Klik op een query voor tijdreeks-grafieken van RAM, CPU en I/O, een uitsplitsing van ProfileEvents, per-thread rol-inferentie (welke threads bezig zijn met aggregatie vs. scannen vs. I/O) en geheugenallocatie-details.
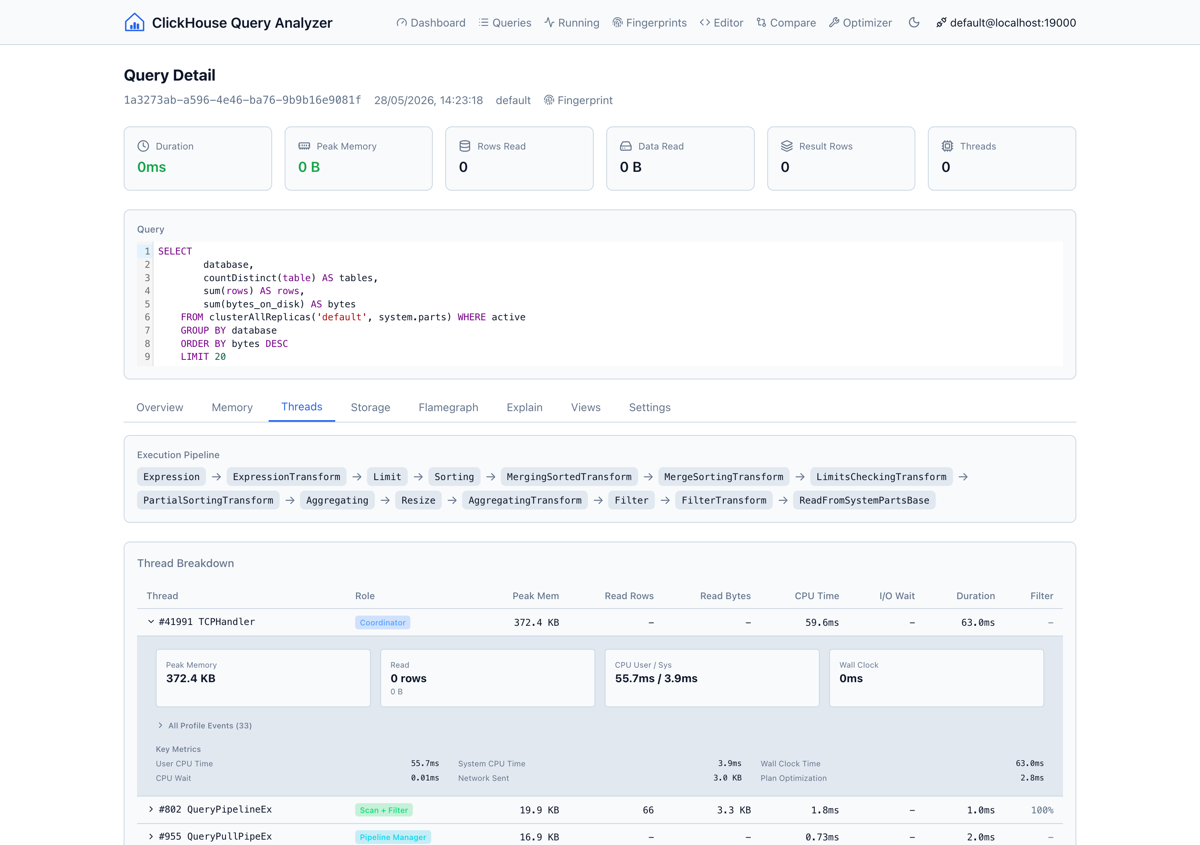
Dit is de weergave die ik steeds miste: zien wat een query écht deed, niet alleen dat het 12 seconden duurde.
Flame Graphs en EXPLAIN
De analyzer bouwt canvas-gebaseerde flame graphs vanuit system.trace_log, met ondersteuning voor vijf trace-types: CPU, Real, Memory, MemorySample en MemoryPeak. Je krijgt het standaard zoom-in-hover-gedrag, zodat je snel kunt vinden waar de tijd aan wordt besteed.
Naast flame graphs is er een interactieve EXPLAIN tree view die het uitvoeringsplan weergeeft als een inklapbare boomstructuur, plus ruwe pipeline en syntax weergaven voor het complete beeld.
Query Fingerprints
Query fingerprints groeperen queries op normalized_query_hash: dezelfde query-structuur, verschillende parameterwaarden. Dit laat je geaggregeerde statistieken per fingerprint zien: aantal, gemiddelde, P50, P95 latency, geheugengebruik en I/O. Drill in op een fingerprint om prestatietrends over tijd te zien op uur- of dagbasis.
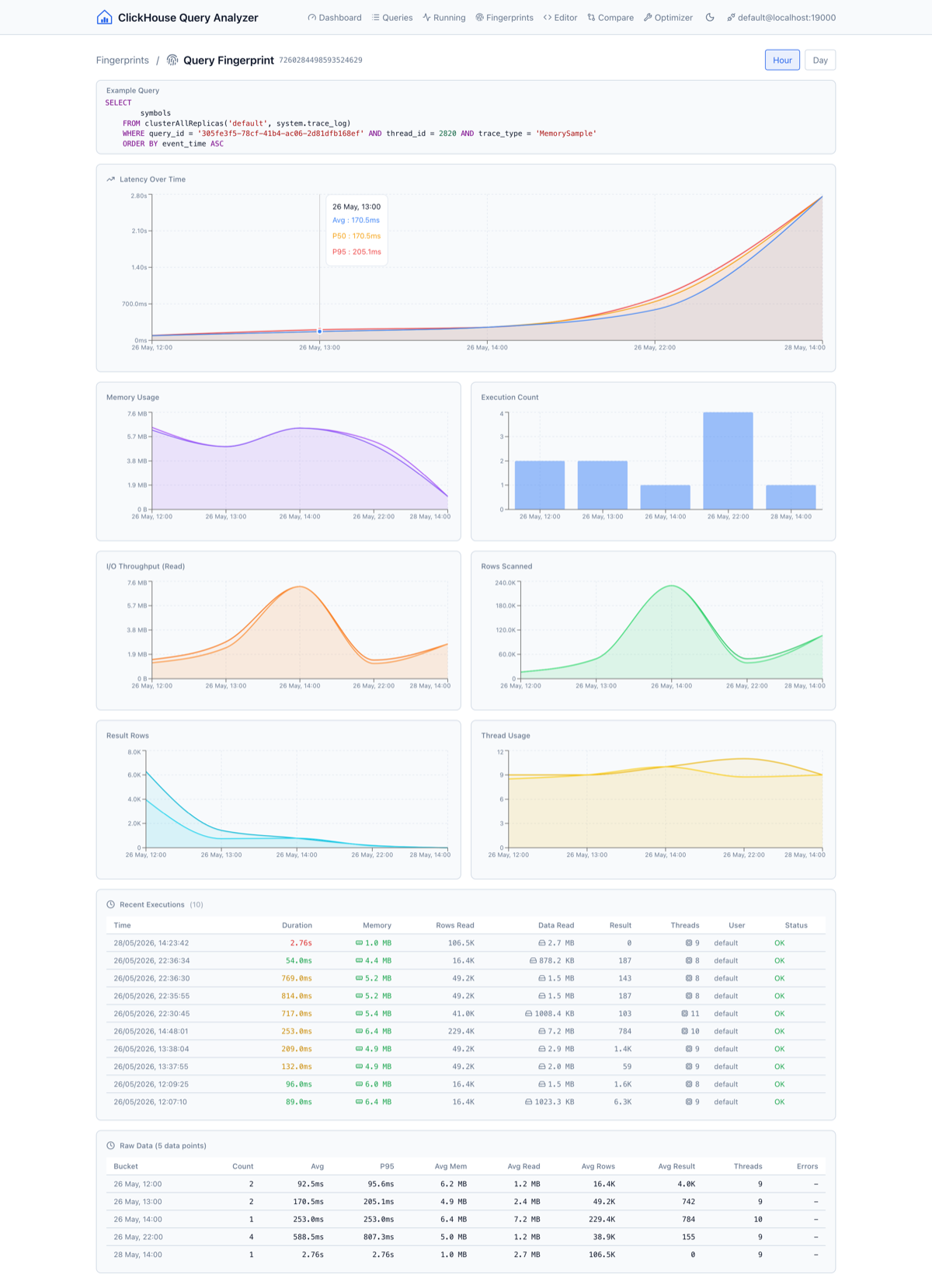
Dit is handig om langzame prestatieverslechtering op te sporen die je nooit zou opmerken als je naar individuele queries kijkt.
SQL Editor
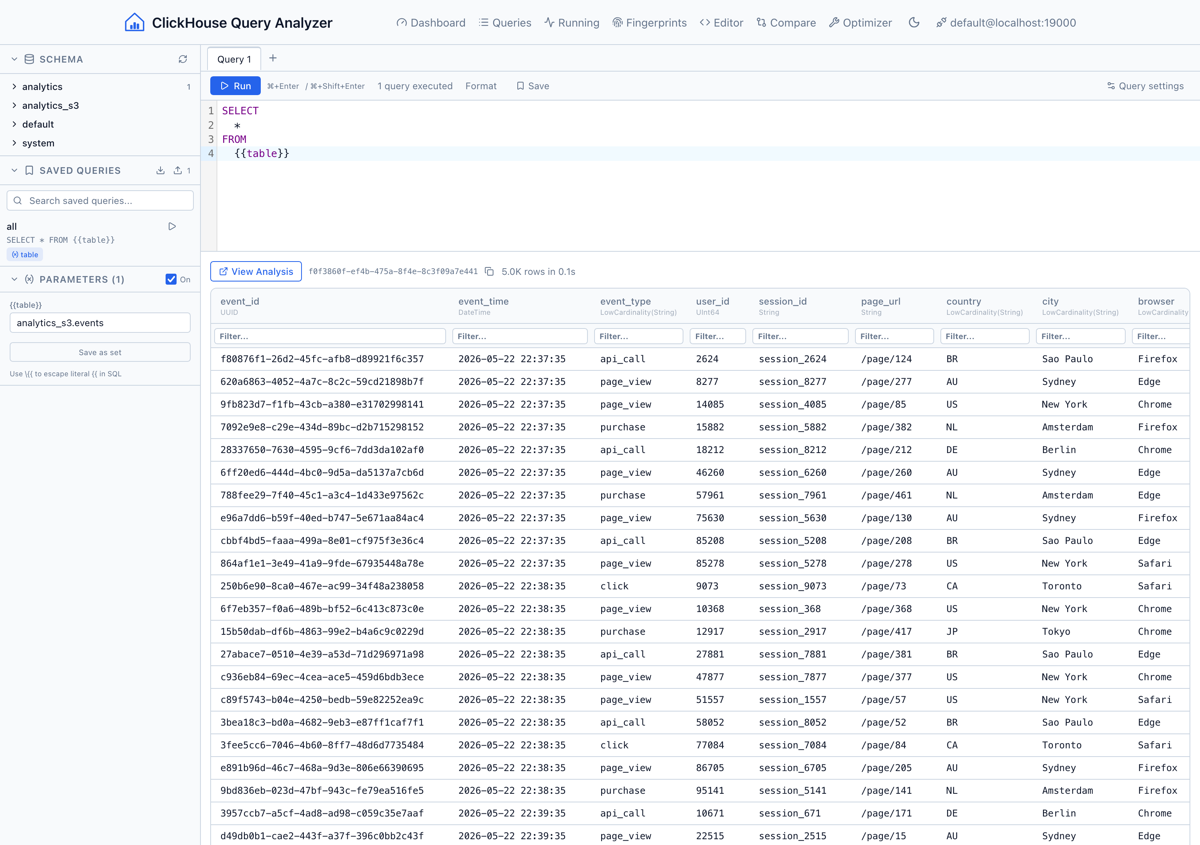
Een volledige CodeMirror 6 editor met een schema browser sidebar die databases, tabellen en kolommen met types toont. Het ondersteunt geparametriseerde queries via een {{param_name}} syntax die automatisch invoervelden genereert. Resultaten linken direct naar de analyse-weergave. Voer een query uit en spring meteen naar de profiling.
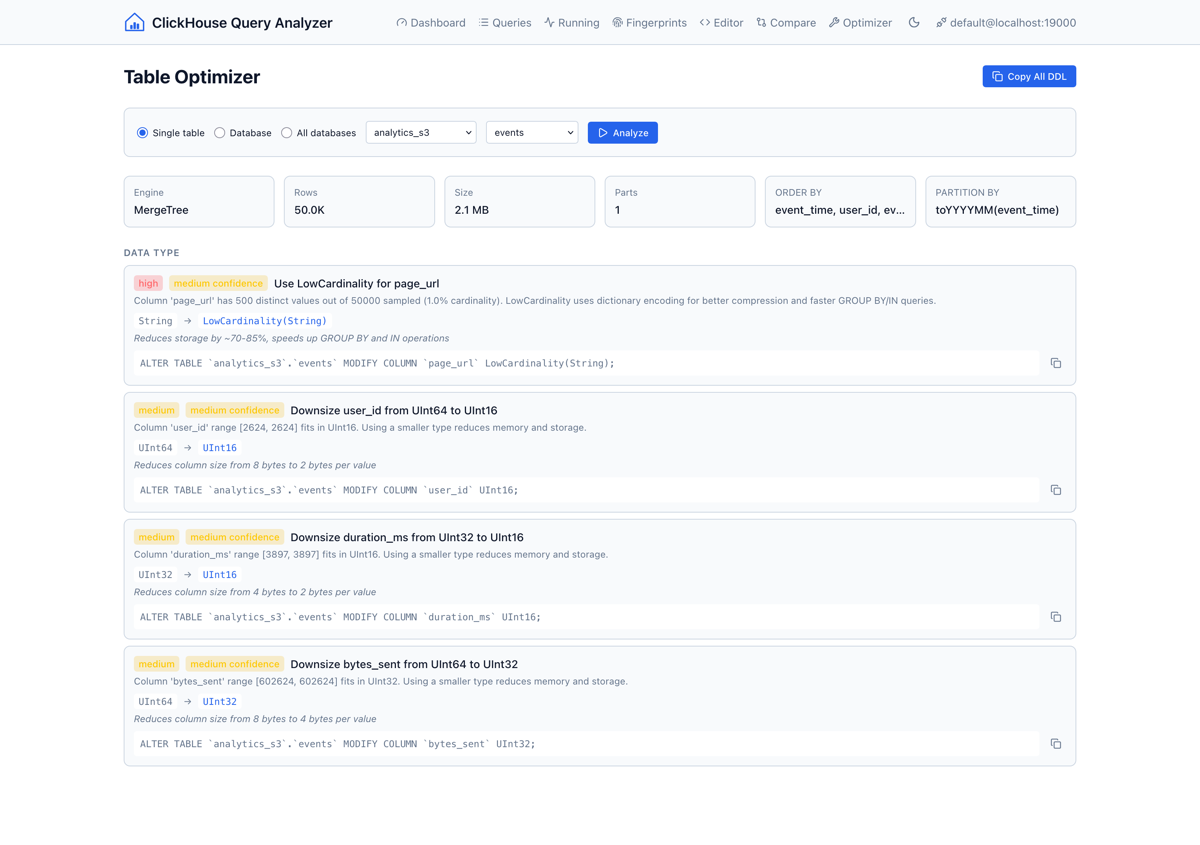
Tabeloptimalisatie
Dit is de feature die zelfs mij verraste in hoe nuttig het bleek te zijn. Wijs de optimizer naar een tabel, een database of alle databases, en hij samplet kolomdata om concrete ALTER TABLE aanbevelingen te genereren:
- LowCardinality wrapping voor string-kolommen met lage kardinaliteitsratio’s
- Integer right-sizing:
Int32voorstellen in plaats vanInt64als de data past - Nullable verwijdering voor kolommen die nul nulls bevatten in de sample
- Codec suggesties: DoubleDelta voor sequentiële timestamps, ZSTD voor hoge-kardinaliteit strings
- Partitionerings- en skipping index aanbevelingen
- Gezondheidscontroles: te veel parts, hoge bytes-per-row ratio
Elke aanbeveling komt met een severity-niveau, confidence-rating en kopieerbare DDL.
Probeer Het
De analyzer is open source en beschikbaar als single binary of Docker image. Geen setup-wizard, geen config-bestand. Gewoon verbinden en beginnen met debuggen.
docker run -p 8080:8080 ghcr.io/nimbleflux/clickhouse-query-analyzer:latestOpen vervolgens http://localhost:8080, vul je ClickHouse verbindingsgegevens in en je bent klaar.
- GitHub: Broncode, releases en documentatie